Prodotti
I prodotti HTS sono il risultato di una richiesta costante da parte di aziende pubbliche e private che necessitano di soluzioni software chiavi in mano, facilmente integrabili con i sistemi esistenti, e compatibili con la normativa italiana e internazionale.
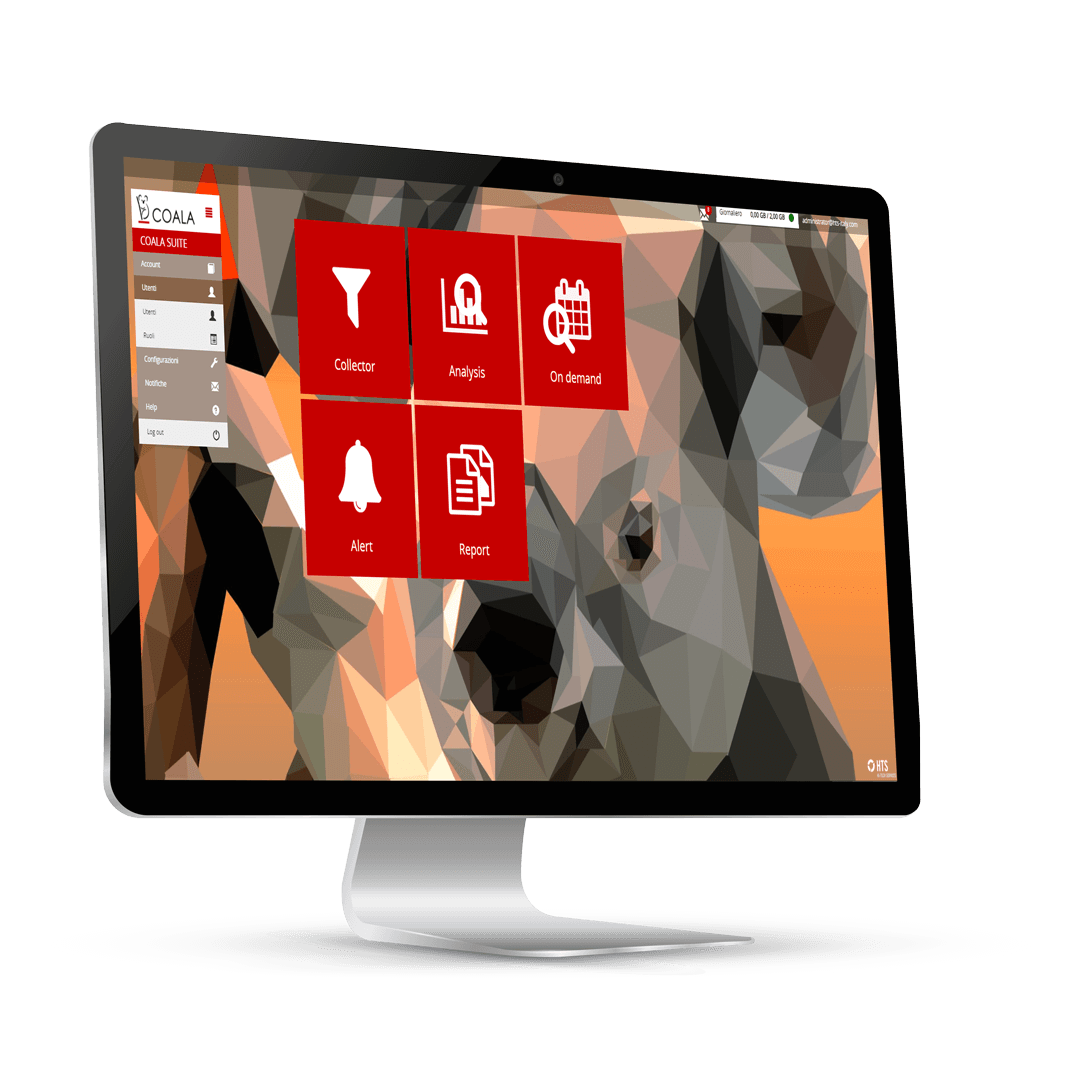



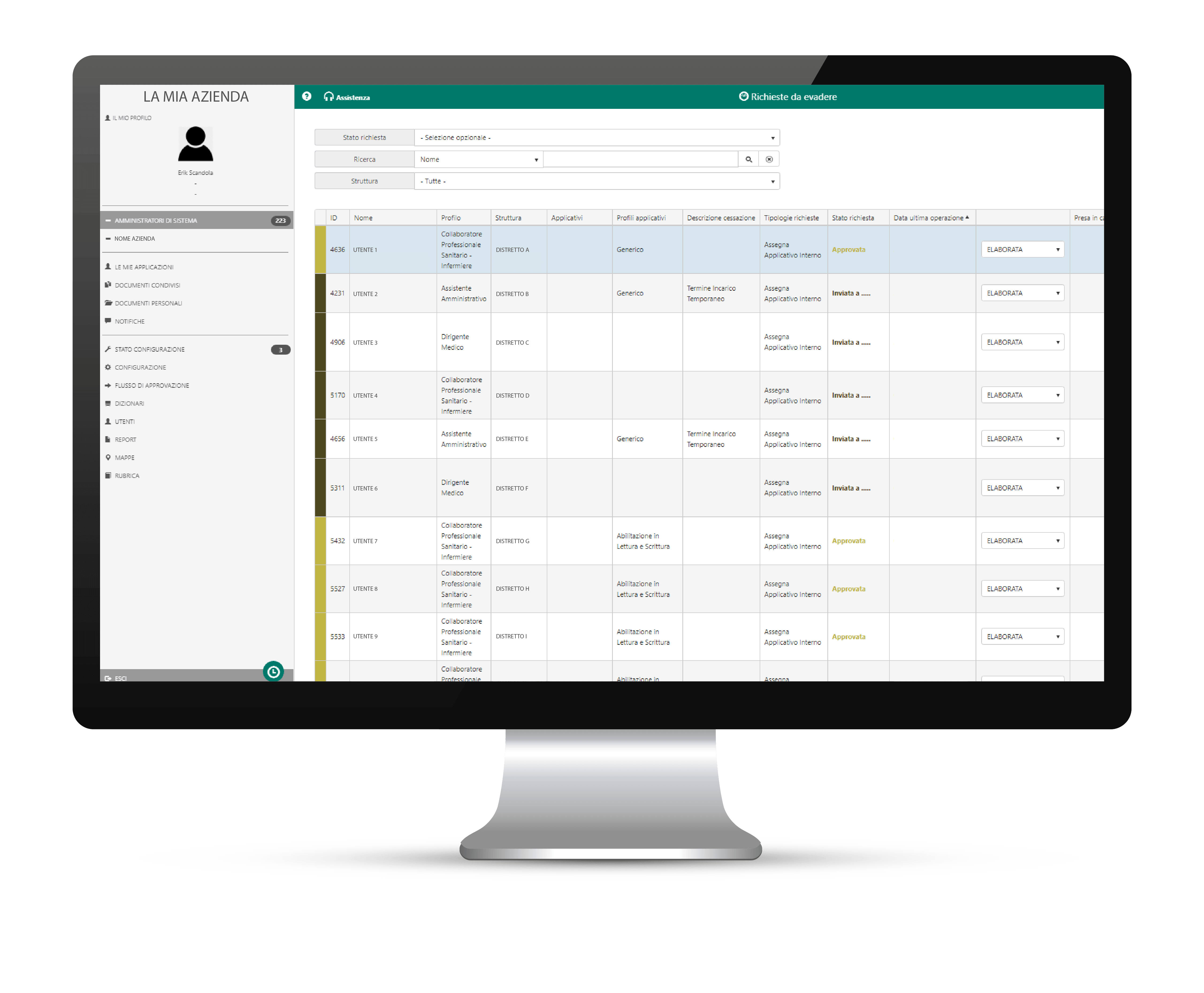

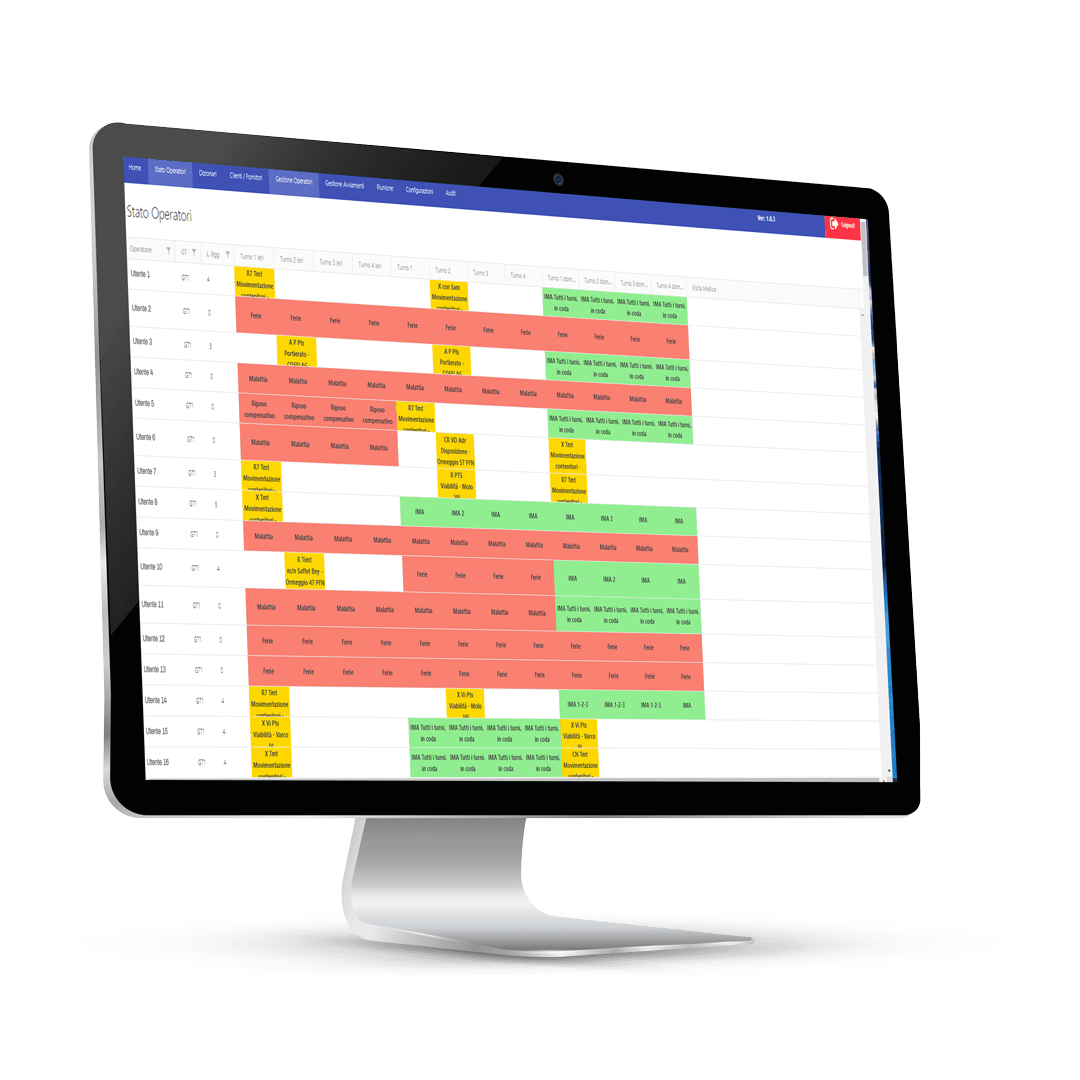

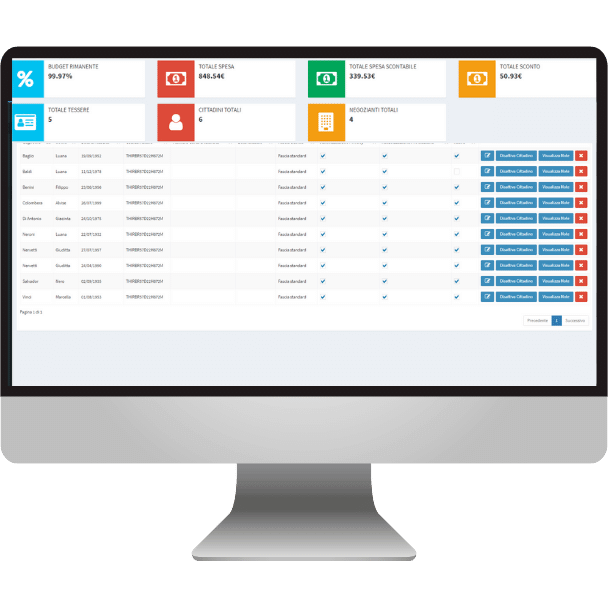




La fabbrica di prodotti HTS è sempre attiva e al lavoro per risolvere problemi complessi con soluzioni semplici!
Mettici alla prova e contattaci!